
通过相同的输入关键字来定位固件系统中的漏洞
- SaTC (Shared-keyword aware Taint Checking)
论文路线图:
0x20 提供了这项工作的动机和背景,并概述了我们的系统。
0x30、0x40、0x50 和 0x60 介绍了我们的数据关系恢复技术和敏感数据流分析的设计和实现
我们通过0x70 中真实世界固件样本的实验和案例研究证明了 SaTC 的功效
我们在第 0x80 节中讨论了 SaTC 的应用场景及其局限性,并将我们的系统与第 0x90 节中的相关工作进行了比较
0x100 总结了论文
有关论文:
karnote
The Art of War
Angr
0x01 Abstract
物联网设备为我们的生活带来了便利,但他们的普及也将安全漏洞带来的影响加剧,嵌入式系统中许多知名漏洞都存在在web服务中,但不幸的是:现有的漏洞检测方法(web scan),无法高效甚至有效的检测分析嵌入式web服务中存在的漏洞,他们要么引入大量的执行消耗,以及会产生误报和漏报。
在这篇论文中,为了能有效的检测在嵌入式系统上的web服务的安全漏洞,我们提出了一种新型的解决方案静态污点分析(satic taint checking 静态污点检测),我们主要做的是:我们发现Web 界面上的字符串通常在前端文件和后端二进制文件之间共享,以对用户输入进行编码。因此我们提取了一些常用的前端关键字,并使用他们在后端定位参考点,来表示输入条目。我们用有针对性的数据流分析来准确检测不可信的用户输入的危险用途。我们实现了一个SaTC的原型,并在6家供应商的39个嵌入式系统固件上完成了对原型的评估。SaTC发现了33个未公布的漏洞,并且其中的30个已经被CVE/CNVD/PSV确认。对比karnote(the state-of- the-art tool),SaTC明显的发现了更多于karnote的漏洞数量在测试阶段。这表明SaTC在发掘嵌入式系统漏洞时是有效的。
0x02 Introduction
物联网设备打开了前所未有的连接之门,为我们的日常生活带来创新的方法和服务。预计2020年将有58亿个物联网终端投入使用,然而,物联网设备的普遍性使漏洞更具破坏性,并导致重大的安全风险。根据报告57% 的物联网设备容易受到中等或高度严重的攻击,这使得这些设备对攻击者来说可以说是唾手可得的成果。在所有物联网设备中,无线路由器和网络摄像头比其他嵌入式设备遭受更多的攻击,关键原因是这些设备暴露了通常包含可利用漏洞的 Web 服务和网络服务。例如,无线路由器通常为最终用户提供基于 Web 的界面来配置系统。底层固件包含一个 Web 服务器、各种前端文件和后端二进制程序。 Web 服务器接受来自前端的 HTTP 请求并调用后端二进制文件来处理它们。在这种情况下,攻击者可能会向前端构造恶意输入,以破坏相应的后端二进制文件。
不幸的是,现有方法无法有效分析嵌入式系统中的服务以检测漏洞。现有方法无法有效分析的难点在于前端和后端之间复杂的交互和隐式数据依赖。动态的解决方案,像:模糊测试(fuzz), 仿真(emulation) 需要提供具体的上下文来运行起后端,但是动态调试只能所有可能的程序状态的一小部分,从而导致大部分的误报。静态解决方案,像:karnote 依赖于前端和后端之间的通用进程间通信 (IPC) 范式(例如,环境变量)定位输入处理代码,并执行集中测试。不幸的是,这些方法可能会导致许多误报,因为它们忽略了存储在前端文件中的用户输入部分。
我们观察到从嵌入式系统中发现错误的关键点是使用 Web 服务的前端来定位处理用户提供的数据的后端代码。
其实大部分的漏洞在前端部分都可以找到对应的输入点(隐式函数,关键字除外(例如:cookie, backdoor)),因此这种分析方法确实更加有效
在这篇论文中我们向大家展示SaTC(Shared-keyword aware Taint Checking 共享关键字感知污点检测),一种新颖的静态分析方法,可跟踪前端和后端之间用户输入的数据流,以精确检测安全漏洞。我们的理解是,处理用户输入的后端函数通常与相应的前端文件共享的关键字:在前端,用户输入被打上关键字并被编码到数据包中;在后端,使用相同或相似的关键字从数据包中提取用户输入。因此,我们可以使用共享的关键字来识别前端和后端的连接,在后端定位用户输入的入口。通过用户输入条目,我们可以应用选择性数据流分析来跟踪不受信任的输入并识别其危险用法,例如将其用作命令,这会导致命令注入攻击。
我的理解:一般路由器这种是启动的一个httpd的web服务,前端提交一个uri请求申请例如:http://ip:port/api/search?query=“xxx” 这种请求的话,一般在路由器中关键字query 会被放在form表单中的name字段,然后由后端会有一个函数来对query进行处理,那么在这里query就是我们用来定位后端污点源头的shared
为了提高嵌入式系统中漏洞检测的速度,我们提出了对传统污点分析技术的三种优化:
- 首先,基于物联网固件的特性,我们开发了一个大致的污点引擎,其中包含针对特定功能的特殊规则,以平衡效率和准确性。
- 其次,我们通过输入引导和跟踪合并来加速路径探索,利用调用图(call graph)和接收函数(sink functions )来优化搜索空间。
- 最后,为了处理特定函数(例如sanitizer function)中的无限路径问题,我们使用优先级算法来有效地处理循环。
我们用三个组件设计 SaTC:
- 一个用于从前端文件中收集关键字的输入关键字提取器
- 一个用于在后端二进制文件中定位输入条目的输入条目识别器
- 一个用于有效检测漏洞的输入敏感污点引擎
我们的原型依赖Ghidra and KARONTE with around 9800 lines of Python code实现,他支持解析多种类型的前端文件包括(HTML,J JavaScript, XML),可以分析广泛使用的后端架构:(Arm mips x86)
未定位二次利用的文件,二次利用(即污点源在传到后端文件的时候断了一次)
为了了解 SaTC 在检测嵌入式系统漏洞方面的功效,我们使用的来自六家厂商的39个固件例子,SaTC成功的在这些固件例子的最新版本中发现了33个未公开的漏洞,其中包括(命令注入漏洞以及溢出漏洞),由于其严重的安全影响,在这些漏洞中,其中有30个已经被确认为 CVE/CNVD/PSV ID。我们也将SaTC与karnote进行了对比实验。在两天测试了7个固件例子后,SaTC一个报出65个点,其中有36个为阳性报点,而karnote未标出任何阳性点。结果表明 SaTC 是一种检测嵌入式系统漏洞的实用工具。
总而言之,我们做出了以下贡献:
-
我们提出了一种新技术: 它利用嵌入式系统前端和后端之间的通用关键字来定位后端二进制文件中的数据入口。
-
我们设计并实现了SaTC: 它利用粗粒度污点分析和路径跟踪合并方法来有效检测嵌入式系统中的漏洞。
-
我们在 39 个真实世界的固件样本上评估 SaTC 并发现 33 个未公开漏洞,包括命令注入、缓冲区溢出和不正确的访问控制错误。
为了促进未来的研究,我们将发布SaTC 源代码以及实验数据在:https://github.com/NSSL-SJTU/SaTC
0x20 Problem and Approach Overview
在本节中,我们首先提供嵌入式系统中漏洞的背景。然后,我们概述了我们的方法并讨论了相关的难点。
Threat Model. 在本文中,我们的目标是从两种物联网设备(无线路由器以及web 摄像头)中检测安全漏洞,这些设备实现了便捷的网络服务和网络服务,以帮助系统管理,配置和数据共享,如果通过MQTT(消息队列遥测传输 Message Queuing Telemetry Transport)和 UPnP(通用即插即用Universal Plug and Play)。 由于这两种类型的设备通常是家庭网络或本地网络的入口,攻击者对它们非常关注并喜欢通过网络服务对其进行黑客攻击,例如,最近的一项研究表明,2018 年 75% 的物联网攻击是针对路由器的,而网络摄像头以 15.2% 位居第二。同时,这些设备中的大多数仍然存在严重缺陷。我们认为攻击者可以获取目标设备的固件副本,但无法物理访问受害设备。它们只能与前端接口通信以影响后端使用的值。后端受到物联网设备上最先进的防御机制的保护,(Executable Space Protection, Address Space Layout Randomiza- tion, and stack canaries)然而,由于资源有限,没有部署先进的机制(例如,软件定义网络、入侵检测系统 )来动态识别这些攻击,即命令注入和内存损坏攻击。
但其实对于大多数mips,arm架构的设备这些保护通常是关闭的,因此也就更加容易攻击
0x21Motivating Example
IoT 设备的 Web 服务通常由两个组件组成,前端和后端。前端向最终用户展示设备的配置和功能,而后端解析从前端接收到的请求并执行相关服务。
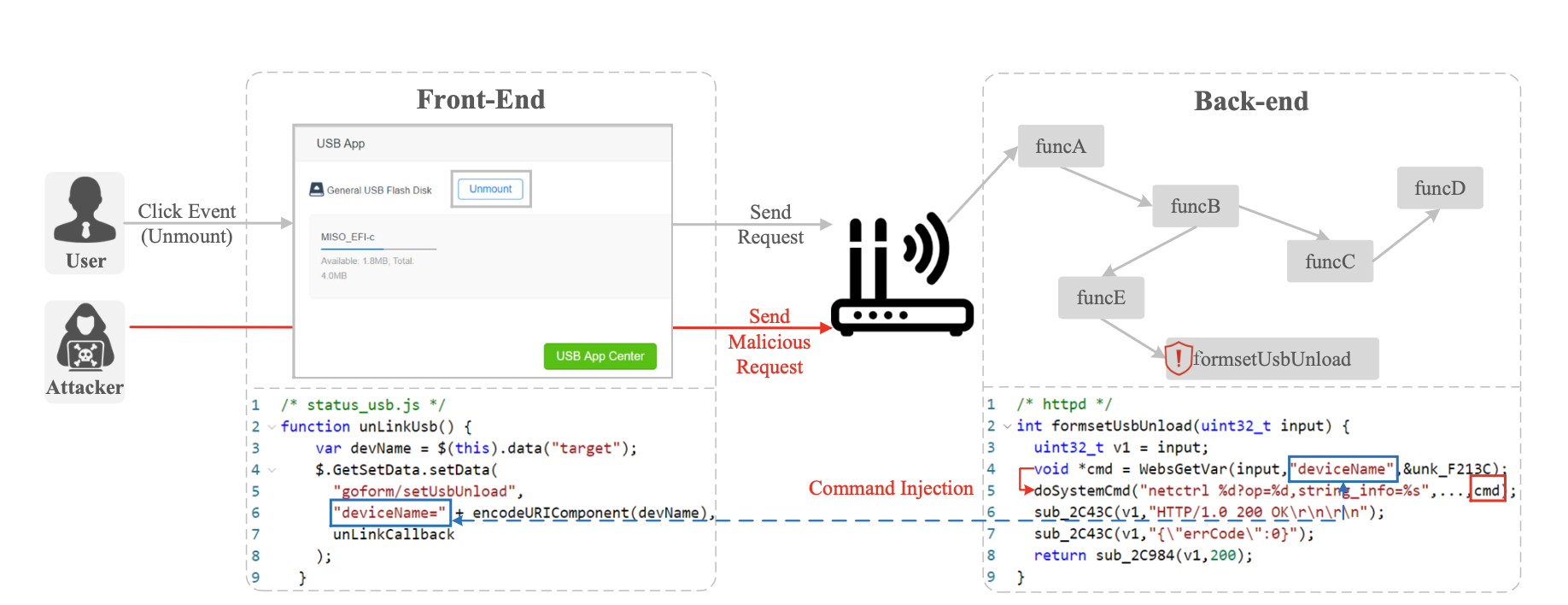
例一:左侧为腾达AC18路由器前端:USB管理接口和网页源代码;右侧显示后端:消息处理过程的调用图。 deviceName 由前端和后端的代码使用。攻击者可以通过发送带有恶意设备名称的请求来注入任意命令。
例一显示了一个示例,其中最终用户利用交互式 Web 界面来管理 Tenda AC18 路由器的外部设备。目前,路由器上安装了一个名为General USB Flash Disk的U盘,用户决定将其移除。在前端 Web 界面中,她只需要单击“卸载”按钮。前端会自动合成一个带有设备名称的卸载请求(左侧 status_usb.js 中的第 4 行),并将请求发送到右侧的后端。后端 Web 服务器将解析请求并调用函数 formsetUsbUnload 来处理请求。函数 formsetUsbUnload 识别设备名称,合成一个命令字符串(httpd 中的第 4 行)并执行命令卸载指定设备(httpd 中的第 5 行)
不幸的是,这个web服务中包含一个典型的命令注入漏洞,由于函数 formsetUsbUnload 无需任何清理检查即可生成卸载命令,因此攻击者可以将额外的命令附加到 deviceName,从而在路由器上运行任意命令。deviceName 22;telnetd -l /bin/sh -p 3333 & forces the back-end program to run two commands: 1) netctrl ... 22 and 2) telnetd -l /bin/sh -p 3333 & 其中第二个命令启动服务器以接受任何未来的命令。此外,攻击者可以通过 URL http://IP:Port/goform/setUsbUnload?deviceName=evalCMD 直接向后端发送恶意卸载命令,表明设备可以被远程入侵。
当前的错误发现技术无法有效检测这些漏洞。动态解决方案,如模糊测试和仿真,不能保证覆盖所有程序状态,并且可能会遗漏许多关键错误。例如,为了使用 SRFuzzer来识别这个 bug,我们必须将 USB 设备插入路由器并触发前端和后端之间的所有正常交互,包括卸载。但是如果我们对路由器不太了解并且忘记检查这些手动操作,那么动态解决方法将有可能丢失检测这个高危漏洞。KARONTE 等静态方法专注于后端二进制文件,并尝试分析所有可能的路径以查找错误。例如,KARONTE 将 Web 服务器和二进制文件之间的通用进程间通信 (IPC) 范式作为分析的起点。然而,大量的IPC接口带来了大量的过度分析,从而导致许多误报。我们需要在后端程序中识别用户输入的真实条目,以进行有针对性的准确分析。
0x22 Observation
在没有一个数据库来记录在后端突出显示用户输入的所有真实条目,我们如何发现示例中的漏洞?我们的直觉是,Web 界面中显示的字符串通常用于前端文件和后端函数:在前端,用户输入被打上关键字并被编码到数据包中;在后端,使用相同或相似的关键字从数据包中提取用户输入。通过这些共享关键字,我们可以连接前端和后端,并从后端识别输入处理功能。从这些功能开始,我们可以执行静态数据流分析并有效识别可利用的错误。
在我们的例一中:前端JavaScirpt文件包含 goform/setUsbUnload ,deviceName 两个字符串,巧合的是,两者都出现在后端二进制httpd中,Listing 1 中提供了后端处理的更多细节。goform/setUsbUnload 被分割车成了两部分字符串,setUsbUnload被用来寻找formsetUsbUnload函数,deviceName被formsetUsbUnload用来获取device name,在前后端相同的关键字:deviceName 和setUsbUnload的帮助下我们可以识别后端中的用户输入处理程序 formsetUsbUnload(第 3 行),并将第 9 行定位为处理输入的起点
int sub_426B8() {
Register_Handler("GetSambaCfg",formGetSambaConf);
Register_Handler("setUsbUnload",formsetUsbUnload);
Register_Handler("GetUsbCfg",formGetUsbCfg);
}
int formsetUsbUnload(uint32_t input) {
uint32_t v1 = input;
void *cmd = WebsGetVar(input,"deviceName",&unk_F213C);
doSystemCmd("netctrl %d?op=%d,string_info=%s",...,cmd);
sub_2C43C(v1,"HTTP/1.0 200 OK\r\n\r\n");
sub_2C43C(v1,"{\"errCode\":0}");
return sub_2C984(v1,200);
}
Listing 1 :例一的后端代码。函数 sub_426B8 注册了几个处理函数,包括处理 USB 卸载动作的函数 formsetUsbUnload
现在,我们可以使用数据流分析技术,比如污点分析:
- James Newsome and Dawn Xiaodong Song. Dynamic Taint Analysis for Automatic Detection, Analysis, and SignatureGeneration of Ex- ploits on Commodity Software. In Proceedings of the 12th Annual Network and Distributed System Security Symposium, pages 3–4, 2005.
- Edward J Schwartz, Thanassis Avgerinos, and David Brumley. All You Ever Wanted to Know About Dynamic Taint Analysis and Forward Symbolic Execution (But Might Have Been Afraid to Ask). In Pro- ceedings of the 31st IEEE symposium on Security and privacy, pages 317–331. IEEE, 2010
- OmerTripp,MarcoPistoia,StephenJFink,ManuSridharan,andOmri Weisman. TAJ: Effective Taint Analysis of Web Applications. ACM Sigplan Notices, 44(6):87–97, 2009.
去跟踪不受信任的输入的使用情况并检测不安全的使用情况。在本例中,我们将 cmd 设置为污点源并跟踪其使用情况。在第 10 行,我们发现 cmd 被用作没有约束的安全关键函数 doSystemCall 的参数。这会触发警报以表示潜在的漏洞。
setUsbUnload 定位sink function formsetUsbUnload -->deviceName传递污点属性给污点源cmd
为了验证我们的直觉是否适用于正常的物联网设备,我们检查了来自五个供应商的 10 个路由器,以检查前端和后端是否使用通用关键字来表示用户输入。具体来说,我们基于以下三个原则从后端和前端提取字符串:
- 我们选择用于对发送到后端的网络包中的用户输入进行编码的前端字符串。具体来说,字符串是网络包中的一些“key”,形式为…&key=value&…。我们在前端手动触发了尽可能多的动作,以覆盖更多的请求消息。
- 我们选择用于从消息中检索输入数据的后端字符串。基于我们对 IoT 固件的了解,我们定义了几个通常用于获取输入值的函数,例如动机示例中的 websGetVar。我们收集这些函数的常量字符串参数作为有趣的后端字符串。
- 我们采用收集前端和后端字符串的交集。对于交集中的每个字符串,我们在前端对关联数据进行变异以触发向后端发送请求消息,并在后端检查关联变量的值。如果后端变量相应地更改其值,我们确认测试字符串是一个共享关键字来表示用户输入。我们多次执行变异以避免意外更改后端变量。
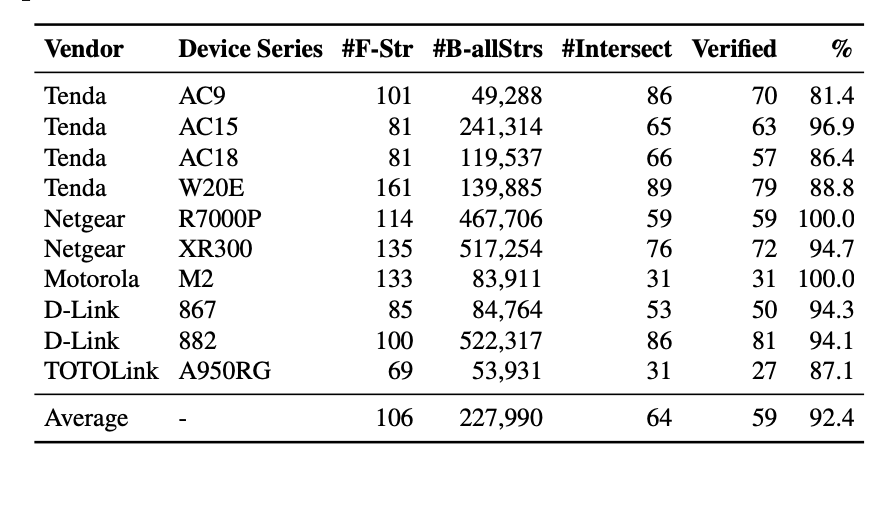
Table 1 :显示我们的验证结果。平均而言,前端捕获的关键字值对中有 92.4% 与后端匹配,这表明我们的直觉适用于这些常见设备。对于两个设备,所有前端字符串都与后端字符串匹配,我们可以完全依赖共享字符串来识别来自后端的输入数据。但是对于其他设备,比如腾达AC9,匹配的字符串只占81.4%,剩下的18.6%我们还需要检查才能得到更准确的分析。
Table 1: Intuition verification F-Strs 表示从前端选择的字符串,用于对用户输入进行编码; B-allStrs 代表后端所有可打印的字符串; Intersection 表示用于在后端检索数据的 F-Strs 字符串; Verified表示前后端确认标记相同数据的交集字符串; % 代表在交点中验证的比例。
0x23 Challenges and Our Approaches
尽管我们的方法对于示例来说似乎很简单,但是当我们将其应用于现实世界的嵌入式系统时存在三个挑战:
- 在前端识别关键字:用户输入通常用隐藏在前端的关键字标记,例如样本中的 deviceName。然而,一个未打包的固件在前端包含数千个字符串。例如,表1中列出的Netgear R7000P的固件包含600多个前端文件和近万个字符串。在没有领域知识(应该是指开发知识)或实际执行的情况下理解每个字符串的语义是具有挑战性的。
- 在后端定位输入处理程序(边界二进制文件):后端二进制文件包含许多函数,其中只有一小部分处理用户输入。同时,它们还包含大量的字符串和相应的参考点。如表 1 所示,每个设备在后端二进制文件中包含超过 40,000 个字符串。因此,在后端识别用户输入的入口点具有挑战性。理想情况下,该点应与用户输入有很强的联系,其位置应接近输入的实际用途
- 跟踪用户输入的海量路径以检测漏洞:为了检测漏洞,我们需要跟踪从输入入口到所有接收器的数据流,其中可能包含大量路径。不幸的是,最先进的分析工具 (karnote, The Art of War)引入了高开销,并且无法处理复杂的控制流图或绕过用户输入清理。我们需要一种有效的数据流分析和路径探索方法。
难点四:跨进程字符串查找
图二:SaTC 的结构。 SaTC 在固件前端搜索以查找输入关键字并在后端定位它们的引用。从参考点开始,SaTC 使用输入敏感的污点分析来发现后端中的漏洞
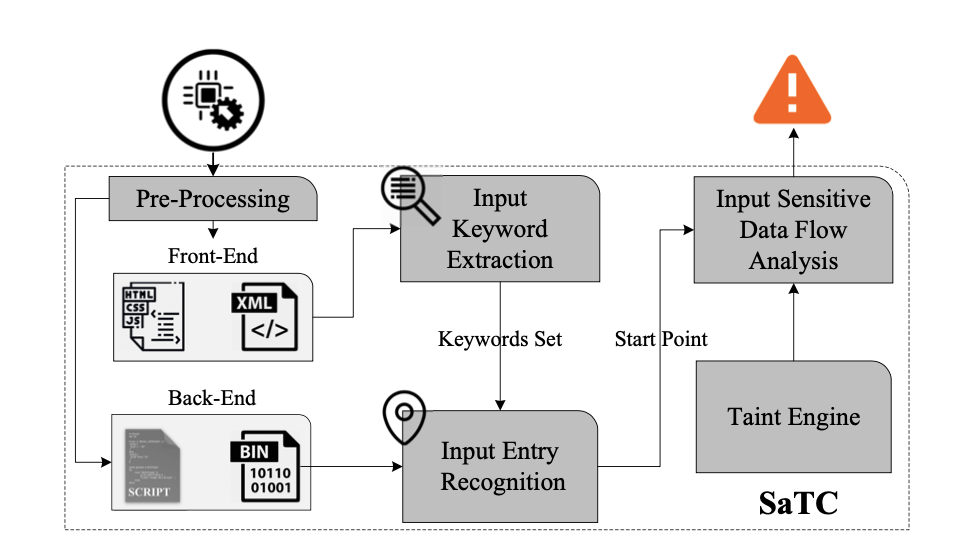
在本论文中,我们设计 SaTC 来解决上述挑战,以有效检测嵌入式系统中的常见漏洞。图 2 提供了我们系统的概览,该系统将固件样本(即整个固件映像)作为输入并生成各种错误报告。作为第一步,SaTC 使用现成的固件解包器(如 binwalk)解包固件映像。从解压后的镜像中,它根据文件类型识别前端文件和后端程序:HTML、JavaScript 和 XML 文件通常是前端文件,而可执行二进制文件和库是后端文件。然后,SaTC 分析前端文件并利用典型模式来提取潜在的用户输入的关键词。在图 1 中,deviceName、target 和 goform/setUsbUnload 将被标识为输入关键字。
之后,SaTC 识别后端的边界二进制文件,根据用户输入的关键字调用不同的处理函数。从这些函数中,我们尝试定位检索用户输入的点。为了找到与用户输入相关的隐式入口点,我们进一步将我们的直觉应用于多个后端程序:用户输入可以通过共享关键字从一个程序传递到另一个程序。这有助于我们跟踪二进制文件之间的隐式数据依赖性。在清单 1 中,第 9 行的代码通过输入关键字 deviceName 解析用户输入,因此 SaTC 将其视为用户输入的一个入口点。最后,我们使用我们的输入敏感污点分析来跟踪不受信任数据的使用情况。我们设计了几种优化来使传统的污点分析在嵌入式系统上有效,包括粗粒度污点传播、输入引导路径选择和跟踪合并技术。当 SaTC 发现用户输入用于任何预定义的接收器时,例如作为系统调用的参数,它会收集路径约束并判断可达性。如果在输入具有弱约束的情况下可以到达接收器,则 SaTC 会发出潜在漏洞的警报。
0x30 Input Keyword Extraction
输入关键字提取
给定一个解压的固件,SaTC 首先从前端文件中提取潜在的关键字。我们根据关键字在后端的使用情况将关键字分为两类:一类用于标记用户输入,如清单 1 中的 deviceName,我们称之为参数关键字;另一种类型是标记处理程序函数,例如清单 1 中的 setUsbUnload,我们称它们为 action 关键字。我们根据不同前端文件中的常见模式识别输入关键字及其类型。我们还对两种类型的关键字应用不同的细粒度规则来过滤误报。
在我们目前的设计中我们考虑了三种前端文件:JavaScript HTML XML :
由于 HTML 文件具有标准格式,因此我们使用正则表达式来提取关键字,例如 id、name 和 action 属性的值。动作属性的值被视为动作关键字。
基于 XML 的服务,例如简单对象访问协议 (SOAP) 和通用即插即用协议 (UPnP),通常在其 XML 文件中使用固定格式来标记输入数据。因此,我们只需要进行预分析,然后使用正则表达式来提取关键字。 XML 正文中第一级标签的名称被视为操作关键字。
JavaScript 的格式是千变万化的,因此正则表达式无法正确识别关键字因此,我们将 JavaScript 文件解析为抽象语法树 (AST) 并扫描每个 Literal 节点以从值属性中提取值。如果 Literal 节点包含符号 /,我们将字符串作为动作关键字。我们进一步搜索所有 CallExpression 节点以找到使用典型应用程序编程接口 (API) 作为其被调用者的节点,例如 sendSOAPAction。匹配节点的 API 方法或参数也被视为操作关键字。使用此方法,从图 1 中的代码中,我们的提取模块将获得 target、goform/setUsbUnload 和 deviceName。
像php文件我认为其是也可以当作前端文件来匹配一定的关键字出来,例如:D-link的php后端有传到cgi中的
从 HTML、XML 和 AST 中收集的字符串包含许多假关键字,这不仅给下一步的字符串匹配带来了很大的负担,而且在错误检测中引入了误报。例如,字符串目标通常在前端使用,但在后端没有对应物。为了过滤无效关键字,我们根据经验设计了几条规则
- 首先,我们删除带有特殊字符的字符串,例如 !和@,前端生成HTTP请求时会转义
- 如果字符串以 = 结尾,我们保留左侧部分并丢弃右侧部分。符号 = 通常用于连接参数和变量,例如图 1 中的 deviceName=,其中只有参数名称会在后端重用
- 我们过滤掉短于阈值的字符串(我们在我们的项目中使用 5做为这个阈值),因为参数关键字和动作关键字通常具有非平凡的名称(就是说不会太短)。
即在一些情况下,前端字符串并不一定会向后端传递,因此为了优化,要对这些字符串进行过滤
筛选后,候选列表中可能仍包含许多未用作输入关键字的干扰项。为了降低后续模块的复杂度,我们使用了两种启发式方法来识别并从关键字集中排除它们,我们将这些关键字从候选列表中删除:
- 如果一个 JavaScript 文件被大量 HTML 文件引用,我们会将其视为一个通用的共享库,就像图表库一样。由于库文件通常不包含输入关键字,我们将忽略此类文件中的所有候选。
- 如果一个关键字被多个前端文件引用,例如Button和Cancel,它可能是一个普通的字符串,而不是一个输入关键字
Border Binary Recognition.(边界二进制文件识别)
在固件后端,边界二进制文件将设备功能导出到前端,同时接受来自前端的用户输入。因此,边界二进制是一个很好的起点供我们分析。根据输入的关键字,SaTC 可以在短时间内识别出边界二进制文件。具体来说,我们从每个后端二进制文件中提取字符串,并尝试将它们与输入的候选关键字进行匹配。我们将具有最大匹配关键字的二进制文件视为边界二进制文件。
0x40 Input Entry Recognition
Web服务器收到前端的请求后,调用相应的处理函数解析输入的数据。数据提取点是后续分析的目标,我们将其定义为输入条目。输入条目识别模块根据对前端关键字的引用检测后端二进制文件中的入口点
公式一:
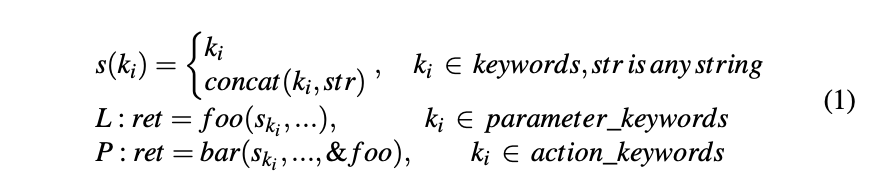
Keyword Reference Locator 关键字参考定位器 公式一显示了我们从后端的边界二进制文件中定位输入条目的方法。 表示一个字符串,要么完全等于一个输入关键字 或包含一个子串,定位器检测引用字符串的边界二进制文件内的位置,由于处理函数通常使用 input 关键字从请求中提取目标数据,SaTC 定位以输入关键字作为参数的函数调用 L,例如 foo(“devName”)。考虑我们在图 1 中的例一,输入关键字提取器将字符串 deviceName 识别为参数关键字,并将 httpd 识别为边界二进制文件。在 httpd 中搜索关键字引用时,如清单 1 所示,我们的定位器发现对 websGetVar 的函数调用使用 deviceName 作为参数(第 9 行)。此函数调用被视为关键字引用位置,因此是一个输入条目。在listing 2 的另一个示例中,在第 2 行,对 webGetVarString 的函数调用使用字符串 SetWebFilterSettings 和参数关键字 WebFilterMethod 的串联作为其参数。因此这个函数调用也是一个输入点。
Listing 2 Pseudocode of NVRAM Operations. 第 2 行的函数调用是输入条目,它使用关键字 WebFilterMethod 的超集来检索输入。
SetWebFilterSettings() {//in binary prog.cgi
pcVar1=webGetVarString(wp,"/SetWebFilterSettings/WebFilterMethod");
iVar2=webGetCount(wp,"/SetWebFilterSettings/WebFilterURLs/string#");
i=0;
(iVar2 <=i) {
/* NVRAM operations */
nvram_safe_set("url_filter_mode",pcVar1); nvram_safe_set("url_filter_rule",tmpBuf);
}
}
upload_url_filter_rules() {//in binary rc
/* NVRAM operations */
iVar1=nvram_get_int("url_filter_max_num");
__s1=(char *)nvram_safe_get("url_filter_mode");
__src=(char *)nvram_safe_get("url_filter_rule");
}
在所有关键字参考中,我们优先处理动作处理程序中的那些关键字。具体来说,SaTC 搜索将动作关键字和函数指针作为参数的函数调用 P。由于动作关键字用于检索特定输入的处理程序,因此我们将函数指针中指定的例程视为动作处理程序。如果参数关键字的某些参考点 L 在这些处理函数内部,我们将优先探索 L。在 Listing 1 中,SaTC 将函数 formsetUsbUnload 定位为动作处理程序,因为第 3 行的函数调用将动作关键字 setUsbUnload 和 formsetUsbUnload 作为参数。因此,作为参考点,formsetUsbUnload 中的第 9 行将在其他条目之前进行分析。
公式二:
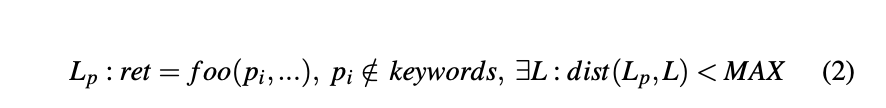
**Implicit Entry Finder ** 隐式条目查找器
在我们的实验中,我们发现后端的几个真实输入条目在前端没有对应的关键字。例如,在listing 3 中,函数 formSetSambaConf 从数据包中检索多个元素,每个字符串都应被视为有效的输入条目,如 password。然而,我们的输入关键字提取模块会找到除 action 和 usbName 之外的所有关键字。在数据中没有动作,第 4 行将返回一个空指针,第 9 行中的条件将始终为假。因此,在正常执行中,第10行的代码注入漏洞永远不会被触发。SaTC 也会错过这个漏洞。但是,攻击者可以在没有前端帮助的情况下直接发送任意请求。因此,他们可以提供包含 action 和 usbName 的恶意请求,并发起代码注入攻击。
listing 3:Pseudocode of implicit keyword sample 前端文件中缺少 action 和 usbName。 SaTC 会将它们识别为隐式关键字,因此可以检测内联 10 的错误。
int formSetSambaConf(uint32 user_input) {
void *data=user_input;
void *usbname;
action=Extract(data,"action",&unk_F213C);
passwd=Extract(data,"password","admin");
premit=Extract(data,"premitEn","0");
intport=Extract(data,"internetPort","21");
usbname=Extract(data,"usbName",&unk_F213C);
if (!strcmp(action,"del")) {
doSystemCmd("cfm post netctrl %d?op=%d,string_info=%s" ,51,3,usbname);
}
}
为了缓解这个问题,我们建议考虑围绕已知输入条目的类似代码模式进行分析。等式 2 展示了我们的想法:如果我们已经识别出一个输入条目 L,那么只要 foo 具有与 L 相似的代码模式,那么围绕 L 的另一个函数调用 foo 将被视为另一个输入条目。我们在这里将缺失的关键字 称为一个隐式关键字。这种方法将帮助 SaTC 检测一些缺失的条目,从而减少错误检测中的漏报。在listing 3 中, action 和 usbName 都将被视为隐式关键字。一旦 SaTC 对其进行数据流分析,它将很容易识别代码注入错误。
Cross-Process Entry Finder 跨进程条目查找器 在数据流分析过程中,我们发现一些输入的数据流可能在进程边界被中断。例如,在listing 2 中,输入 pcVar1 保存在一个进程 prog.cgi(第 7 行)中的非易失性随机存取存储器 (NVRAM) 中,然后在另一个进程 rc 中从 NVRAM 中检索(第 14 行)。幸运的是,我们可以再次应用我们最初的见解来连接不同流程的数据流:数据保存位置和数据检索位置通常共享相同的关键字。在listing 2 中,prog.cgi 和 rc 都采用 url_filter_mode 来共享 pcVar1,并使用 url_filter_rule 来传递给 tmpBuf。
基于 shared 关键字,我们可以连接设置或使用相同用户输入的不同二进制文件或函数。与原始输入参考点(第 2 行)相比,第 14 行用户输入的第二次检索更接近于真正的sink函数(在列表中跳过)。从这一点开始 taint-track 将大大节省分析工作。
SaTC 使用跨进程条目查找器(或 CPEF)来跟踪跨固件文件或组件的用户输入。具体来说,它搜索使用共享字符串标记数据的各种进程间通信范式,并建立从设置点到使用点的数据流。 CPEF 提供必要的逻辑来检测通信范式(例如,NVRAM 通信)以在二进制文件或函数之间共享数据。它主要支持两种类型的进程间通信范式:
- Nvram NVRAM 是一种 RAM,可在主机设备断电后保留数据。它通常保留设备的用户配置。 CPEF 标识所有 nvram_safe_set 和 nvram_safe_get 函数以构建跨进程数据流。在清单 2 的示例中,prog.cgi 和 rc 之间的数据依赖是通过 NVRAM 操作构建的
- Environment variables. 进程可以通过环境变量共享数据,其中关键字是变量名。 CPEF 遍历程序路径,并收集所有设置或获取环境变量(例如 setenv 或 getenv)的函数调用。如果环境 setter 和 getter 共享相同的变量名,它会在环境设置器和获取器之间建立数据流
其中从环境变量中读取解决跨进程的方法在karnote的论文中有提到,这篇论文与karnote有一定联系,可以对比一下
0x50 Input Sensitive Taint Analysis
SaTC 利用路径探索和污点分析技术来跟踪输入数据以检测后端的危险使用。如表 2 所示,我们基于固件的独特特性设计了三种优化,以平衡效率和准确性,并加快路径探索。
表二:高效污点分析的优化(Optimizations for efficient taint analysis):我们将三种技术嵌入到传统的污点分析技术中,以提高分析嵌入式设备的效率和准确性

0x51 Coarse-Grained Taint Engine
为了对用户输入执行轻量级数据流分析,我们根据三个原则构建了污点引擎:
- 污点源应该与用户输入相关
- 平衡分析的准确性和效率
- 只跟踪从源到潜在接收器的数据流
Taint Source 污点引擎根据输入条目识别的结果标记污点源。污点源可以是目标函数的变量或参数。如listing 1 所示,字符串 deviceName 用作函数 WebsGetVar 的参数,因此其内存位置将被设置为污点源。由于 SaTC 分析的起点是二进制代码片段,因此通常很难识别存储用户提供数据的变量或结构。但是,通过我们基于输入关键字的污点源,SaTC 可以轻松获取用户输入数据的数据流
**Taint Specification.**污点规范, SaTC 的污点引擎在指令级别传播污点属性。我们基于多架构二进制分析框架 angr 实现了它。影响污点分析效率和准确性的主要因素是函数调用的污点规范。为了恰当地处理函数调用,我们首先将函数分为以下几类:可汇总函数、通用函数和嵌套函数。 summarizable 函数是与内存区域操作相关的标准库函数,例如 strcpy 和 memcpy。我们可以很容易地总结出这些功能的效果。通用函数在其主体中不包含函数调用指令或仅包含可汇总函数的分支(例如,图 3 中的 funcA)。其余的函数,包含通用函数的函数调用指令,是嵌套函数。在图 3 的代码中,函数 strcpy 和 strlen 被视为可汇总的函数。 funcA 不调用不可汇总的函数,因此它是一个通用函数。 funcB 调用另一个通用函数 funcC,因此是一个嵌套函数。
图片3: Taint specification for different types of functions 左侧显示了一个示例程序,而右侧显示了污点传播规则的应用。 T(A)表示A的污点标签

我们设计了算法 1 (表二下面)来处理各种函数调用和指令。如果指令 Ins 不是函数调用,则污点引擎将使用相应的污点规则(第 19 行)处理它并更新污点映射 Taint_Map。对于数据移动指令,污点引擎会将污点属性从源操作数传播到目标操作数。对于调用函数func的指令Ins,如果一个实参param包含污点属性(第5行),污点引擎将跟踪func对污点图的影响。如果 func 是可汇总函数,则 SaTC 将其视为指令并应用基于其语义构建的污点规则(第 8 行)。如果 func 是一个通用函数,那么 taint 引擎将进入它的函数体并跟踪从入口点到结束点的数据流(第 16 行)。对于嵌套函数,如果污点引擎进入其函数体并跟踪更多嵌套函数的数据流,分析将过于耗时。因此,我们直接将参数的属性传播到其计算结果中以平衡效率和准确度(第 9~14 行)。具体来说,如果函数在返回值 retv 中返回其结果,我们将用 retv 标记所有参数的属性;否则,我们将 taint 属性传播到所有指针参数。
0x52 Efficient Path Exploration
SaTC 专注于检测两类漏洞:内存损坏错误(例如,缓冲区溢出)和命令注入。为了检测前一类,我们首先在二进制文件中找到类似 memcpy 的函数,并将它们视为接收器函数。 memcpy-like 函数是指在语义上等同于 memcpy 的函数,如 strcpy。然后,如果攻击者控制的数据不安全地到达类似 memcpy 的功能,比如未经清理,我们就会发出警报。例如,对于 memcpy 函数,如果攻击者控制的数据可能影响源缓冲区的长度值,SaTC 将发出警报。为了检测后一类漏洞,我们检索保护接收器功能(例如,类似系统的功能)的条件。然后,我们检查攻击者是否可以构建(PoC)来绕过约束。如果是这样,我们会发出警报。
https://firmianay.gitbooks.io/ctf-all-in-one/content/doc/8.25_angr.html 静态分析可以得到漏洞的地点,但不能得到触发漏洞的输入
Sensitive Trace Guiding 敏感数据引导 尽管以前的模块减少了污点分析的目标,但仍有相当数量的输入条目需要分析。为了提高分析效率,SaTC 在探索任何路径之前搜索每个目标的汇调用轨迹。接收器调用跟踪表示调用图中从输入条目到潜在接收器函数的函数调用序列。 SaTC根据函数的调用树搜索函数的sink调用轨迹,调用树以函数为根节点。如果一个函数不包含调用跟踪,则没有从该函数到汇点的可达路径。 SaTC 将从目标集中删除此函数内的所有输入条目。在探索过程中,SaTC 会检查每个函数调用指令,以查看目标是否属于调用跟踪。如果是这样,我们将探索导向函数体。
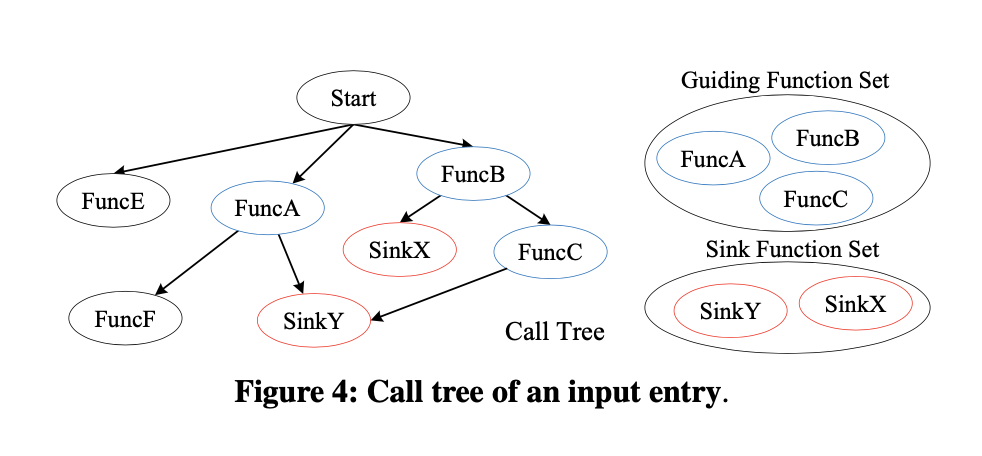
Call Trace Merging. 合并跟踪调用,从一个输入条目开始,可能会有大量的调用跟踪,其中许多调用跟踪共享一些公共路径。为了减少分析工作,SaTC 尽可能地将呼叫跟踪与相同的输入条目合并。具体来说,如图 4 所示,我们首先根据起点和输入关键字对所有轨迹进行聚类。其次,我们将调用轨迹中的所有函数分为汇函数和引导函数两大类,并记录函数调用指令的类型和地址。引导函数表示接收器调用跟踪中接收器函数的支配者。在探索过程中,当我们遇到跳转到引导函数的调用指令后,SaTC会进入该函数进行细粒度分析。否则,它将会把污点规范和策略(在算法 1 中定义)应用于调用指令。
图四:
0x53 Path Prioritization Strategy
在我们的评估过程中,我们发现某些特定功能对路径探索的准确性和效率有重大影响。例如,消毒器函数可能会导致无限循环,而解析器函数可能会引入污染不足问题 [34]。为了减轻这些特定功能的负面影响,我们识别它们并应用特殊规则。具体来说,如果:
- 一个函数至少包含一个循环
- 函数的比较指令数大于阈值
- 部分比较指令可能会限制函数参数指向的内存区域的内容(即值)我们将其视为类似 memcmp 的函数。
根据信息保存的数量,我们可以将这些功能分为两类: parsers and sanitizers.
Parsers 解析器函数通常包含一个循环,例如图 3 中的 funcA。如果变量 s1 不受约束,则始终存在从 default 语句到 for 循环开头的路径。在这些路径中,只有那些通过第一个 case 语句(第 5 行)的路径会在函数外传播污点。换句话说,缺少这些路径的分析将错误地确定用户输入不能影响变量 s2 和以后的执行路径。 SaTC 使用与 KARONTE 相同的解决方案来处理这个问题,它对函数内的那些路径进行赋值,这些路径可能也会在函数外传播污点。
sanitizers. 消毒功能要么清除恶意数据,要么就潜在威胁发出警告。考虑图 5 中的示例,为了过滤特定的字符串,例如 ?,Netgear 在类似系统的函数之前插入了一个 sanitizer 函数 FUN_7b83c。它包含对 user_input(第 7 行)的复杂检查。 while 循环和比较操作会产生许多路径。然而,为了获得对 user_input 的完整约束,我们只对最长路径感兴趣。
这里的最长路径应该理解为走到leafnode的路径
图五:Pseudocode of sanitizer function. 此函数尝试在程序调用类似system的函数之前从用户输入中删除无效字符。
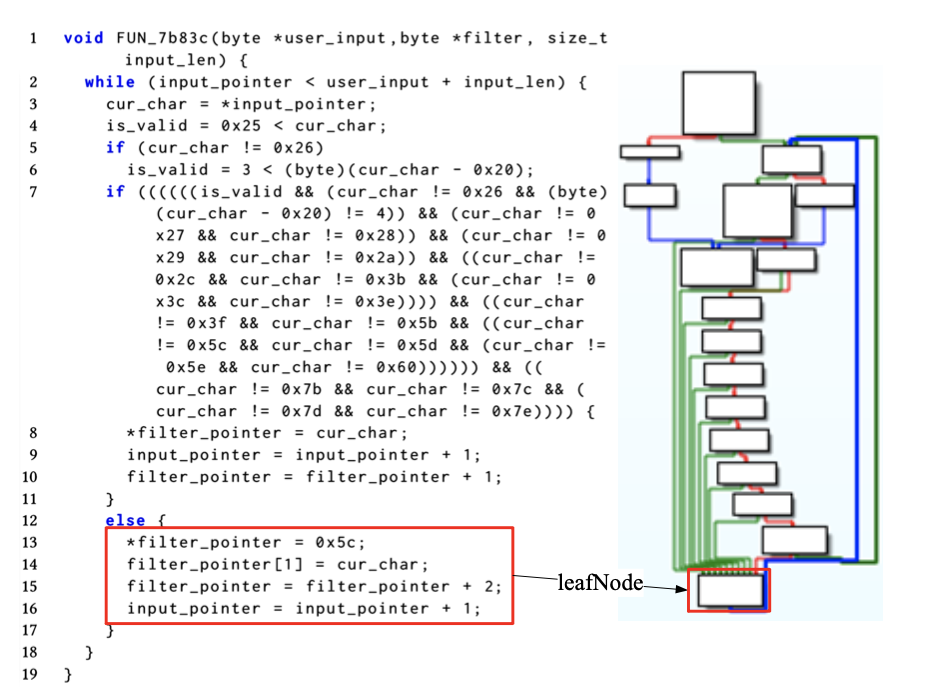
我们使用算法 2 来探索最长路径并获得约束。 rootNode 是函数的起始基本块。首先,它使用 Random_Walk_Search 函数在有限的总次数 Max 内探索可达路径和基本块访问节点(第 8 行)。 Random_Walk_Search 从 rootNode 中随机选择一个后继并递归调用自身,直到遇到一个 LeafNode 并记录该 LeafNode(第 9 行)。 LeafNode 代表没有后继的基本块或循环后边缘的源基本块。其次,它扫描所有的leafNode,如果其入度数大于阈值N(第13行),则删除该leafNode。最后,它重新探索该函数并输出最长路径的约束(第 17 行)。如图 5 所示,复杂检查的 else 分支是一个 LeafNode。
算法二:

0x60 Implementation
我们用大约 9800 行 Python 代码实现了原型系统。输入关键字提取模块是基于标准的 XML 处理库和 JavaScript 解析库 Js2Py 实现的。输入条目识别模块是基于 Ghidra 库和扩展的 KARONTE 的 CPF 实现的,该 CPF 覆盖了与 NVRAM 的共享污染变量。输入敏感分析的污点引擎建立在 angr 之上,这是一个多架构二进制分析框架。路径选择部分基于 Ghidra 库实现。为了让 SaTC 更适用于 MIPS 架构,我们修复了 angr 的二进制加载器和 KARONTE 的寄存器滥用问题。现在,原型系统支持多种架构,包括x86、ARM和MIPS。
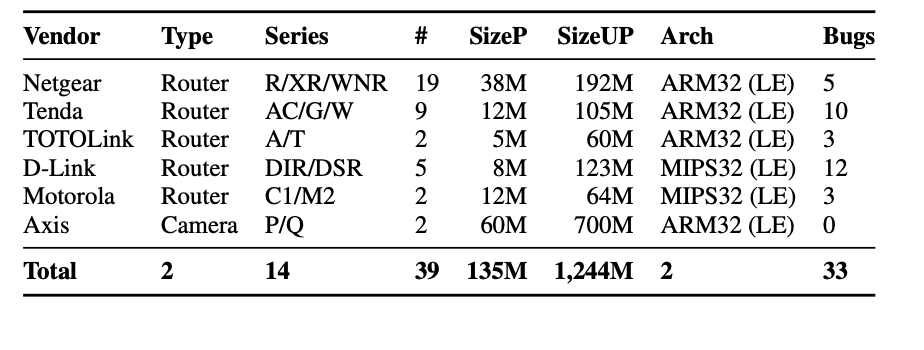
表三:Dataset of device samples. 我们从 6 个供应商处选择了 39 个设备样本,包括 37 个路由器和两个架构的两个摄像头。 SaTC 发现了 33 个以前未知的错误,其中 30 个已被开发人员确认。 SizeP 和 SizeUP 分别代表解包前后的平均大小。
0x70 Evaluation
我们在现实世界的嵌入式系统上评估 SaTC 以回答以下研究问题:
- Q1:SaTC 能找到真实世界的漏洞吗?效果如何——是否与最先进的工具相比? (第 7.1 节)
- Q2:能否准确检测输入的关键字?(第 7.2 节)
- Q3:我们的污点分析的效率和准确性如何? (第 7.3 节)
Dataset. 为了评估我们的方法,我们选择了六家在线提供设备固件的主要物联网供应商,特别是 Netgear、D-Link、Tenda、TOTOLink、摩托罗拉和Axis。如表 3 所示,我们最终收集了 14 个系列的 39 个固件样本,包括 37 个路由器和 2 个摄像头。在样本中,32 个采用 ARM32 架构,另外 7 个采用 MIPS32 架构。平均而言,每个固件为 26 M,而 SaTC 总共处理了 1,024 M。
Existing Tool. 我们将我们的工具与 KARONTE 进行了比较,KARONTE 是用于嵌入式系统的最先进的静态错误猎手。它监控固件后端中多个二进制文件之间的交互,并利用污点分析来跟踪二进制文件之间的数据流以检测漏洞。
Bug Confirmation. SaTC 产生的每个警报都包含从起点到接收器函数的调用跟踪,以及相应的输入关键字。我们根据路径在后端是否可达来区分真阳性和假阳性。如果我们可以根据警报手动生成崩溃证明 (PoC) 并在物理设备上对其进行验证,我们会将真阳性视为真正的错误。
0x71 Real-world Vulnerabilities
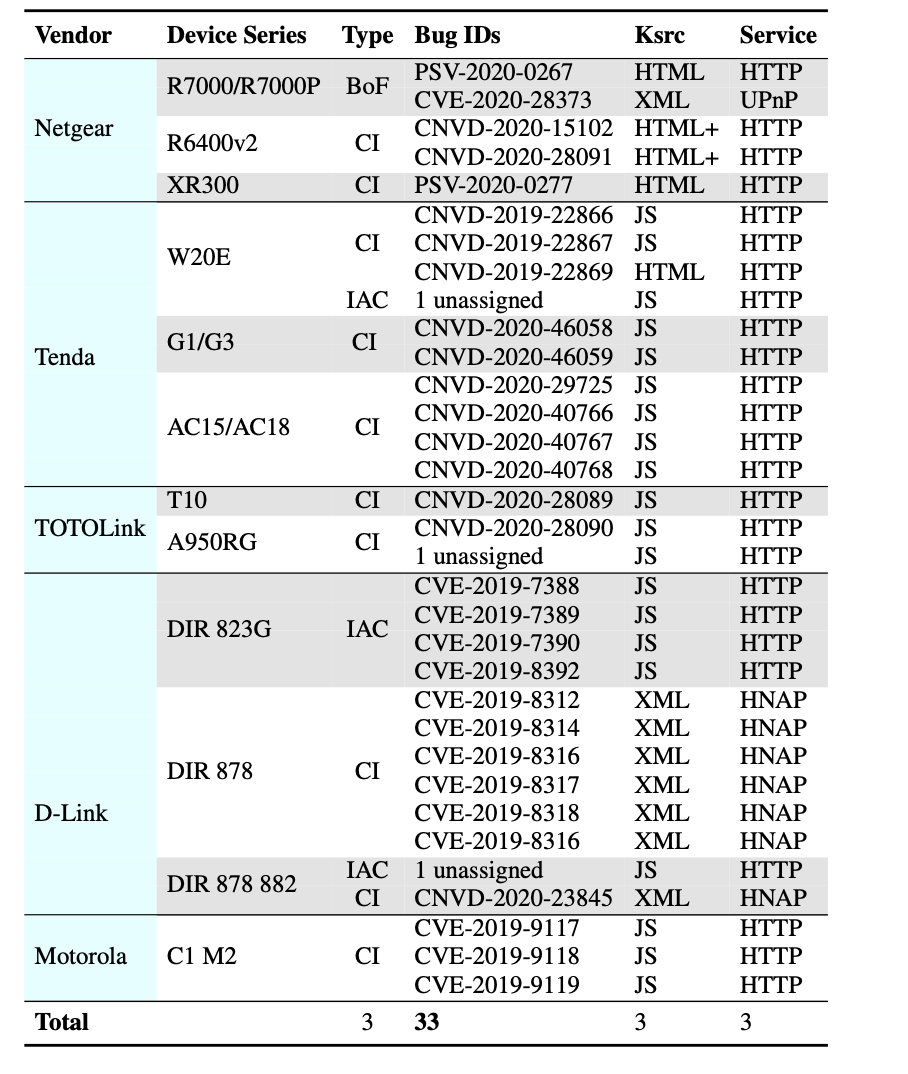
如表四所示,SaTC 检测到 33 个以前未知的错误,在撰写论文时,其中 30 个已被开发人员确认。 25 个错误是命令注入漏洞;其中两个是缓冲区溢出错误;其他六个属于不正确的访问控制,可能导致隐私泄露。随着我们定义更多与类系统功能相关的接收器,我们的工具发现了比其他类型更多的命令注入漏洞。30 个漏洞因其严重的安全后果而分配了 CVE/CNVD/PSV 编号,而开发人员仍在积极检查另一个漏洞。最后一列显示 SaTC 检测到漏洞的服务。除了常见的 HTTP 协议之外,SaTC 还支持其他服务,例如 UPnP 和 HNAP。这些结果表明 SaTC 可以有效地发现嵌入式系统的各种网络服务中的常见漏洞。
表四: Vulnerabilities discovered by SaTC. 对于 bug 类型,BoF 表示缓冲区溢出; CI代表命令注入; IAC 表示不正确的访问控制。 Ksrc 表示找到漏洞相关关键字的前端文件的类型。服务代表发生漏洞的服务。
Comparison with KARONTE. 我们将 SaTC 与最先进的静态分析工具 KARONTE 在发现漏洞方面进行了比较。我们使用KARONTE发布的数据集1和实验结果,其中包括四大物联网供应商(即Net-gear、TP-link、D-Link和Tenda),共49个固件样本。表 5 显示了我们的评估结果。 SaTC 发出了 2,084 条警报,其中 683 条是真阳性; KARONTE 产生了 74 个警报,其中 46 个是真阳性。结果表明,与 KARONTE 相比,SaTC 可以找到更多的真阳性。在设计层面,SaTC采用了与KARONTE类似的方法,两者都依赖公共字符串来连接物联网设备的不同组件:KARONTE使用多个后端二进制文件之间的公共字符串来连接数据流,而SaTC则标识了物联网设备之间的公共标识符。前端和后端定位用户输入的条目。然而,最终结果的差异是显着的。由于 SaTC 可以分析前端文件以揭示后端的输入条目,我们可以显着找到更多的分析点进行污点分析,从而提高错误检测能力。相比之下,后端二进制文件中由 KARONTE 标识的常见字符串不能保证与用户输入相关。因此,KARONTE 存在分析效率低下的问题,漏掉了很多错误。
表五:Compared with KARONTE on its dataset. 对于每个供应商,我们报告设备系列、固件样本数量、平均分析时间(小时)、警报总数 (#Alert) 和真阳性总数 (#TP)。
表六:Compared with KARONTE. 我们列出了分析时间 (min)、警报数量 (#Alert) 和真阳性 (#TP)。
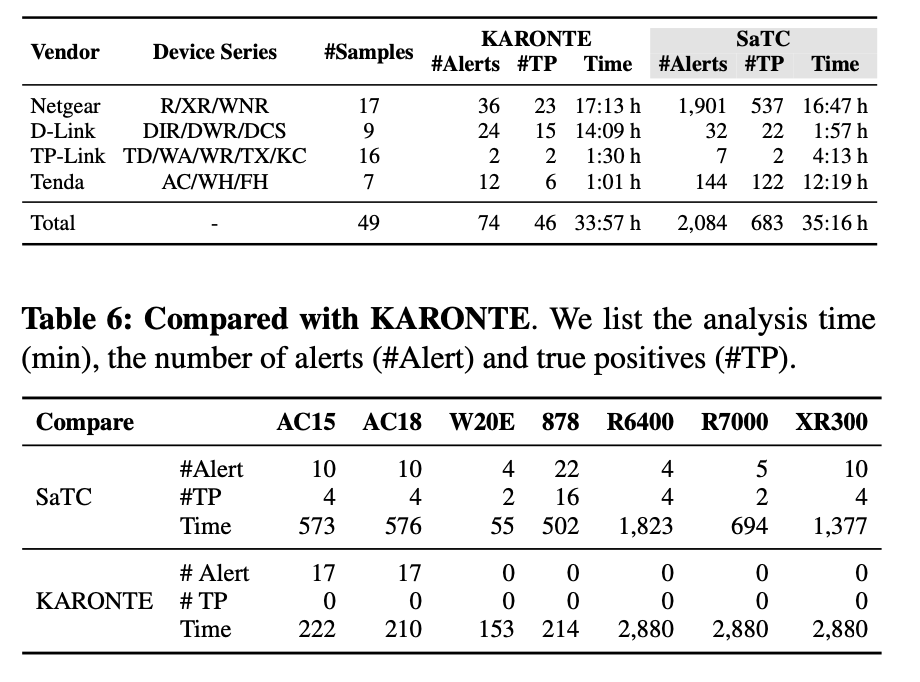
我们进一步选择了来自 3 个厂商的 7 个新固件样本,分别是 Tenda、D-Link 和 Netgear,以证实 SaTC 在更多 IoT 设备上的优势。我们运行 KARONTE 和 SaTC 直到它完成分析或超时(2 天),并将 SaTC 设置为仅检测命令注入漏洞。结果如表 6 所示。 SaTC 成功发现了 36 个真阳性,而 KARONTE 在任何样本中都没有发现任何真阳性。对于 AC15 和 AC18,KARONTE 提供了 17 条到接收器地址的路径。我们手动验证了所有警告都是误报。对于 W20E,KARONTE 没有发现潜在的漏洞。 KARONTE 在 D-Link DIR 878 中没有发现任何边界二进制文件,因此无法发出任何警报。对于 R6400、R7000 和 XR300,KARONTE 无法在 48 小时内完成分析。我们发现它在分析基本块时挂起,因此没有发现漏洞。这些结果表明 SaTC 在发现嵌入式系统中的漏洞方面优于 KARONTE。
我们进一步手动检查了仅由我们的工具发现的警报(在表 5 中),并确定了 KARONTE 错过它们的根本原因。首先,SaTC 和 KARONTE 采用不同的特征来识别边界二进制文件。具体来说,KARONTE 使用指令和函数的特征来识别边界二进制文件,而 SaTC 则考虑从前端文件中提取的字符串。这些不同的启发式方法导致 KARONTE 和 SaTC 选择不同的边界二进制文件。例如,在 Tenda AC 系列中,SaTC 选择 httpd 作为边界二进制文件,而 KARONTE 选择 app_data_center。 SaTC 发出了 144 条警报,但 KARONTE 错过了这些警报。其次,SaTC 和 KARONTE 确定了不同的切入点。 KARONTE 侧重于二进制文件之间的共享数据,而 SaTC 侧重于用户输入的入口点。例如,SaTC 在 Netgear R6400 的边界二进制 httpd 中找到了关键字 ed_url,该关键字标记了用户输入,而 KARONTE 无法找到该关键字并导致假阴性。再举一个例子,对于Netgear R7900中的关键字http_user,KARONTE和SaTC都可以找到相同的缓冲区溢出错误(即SaTC和KARONTE报告中的trace相同)。但是,由于 KARONTE 错过了与字符串相关的入口点,SaTC 可以找到另一个缓冲区溢出错误。最后,KARONTE 无法检测任何命令注入漏洞,因为它不跟踪从输入入口点到类系统功能的数据流。例如,KARONTE 在 Netgear R7300 中错过了 12 个命令注入警报。
SaTC 检测出Tenda AC15/18 两款路由器的四个漏洞可以去跑一下他的工具并复现一下以及Netgear R7300的漏洞
在分析时间上,KARONTE和SaTC各有优劣。 SaTC 的分析时间取决于设备使用的协议和它提取的敏感输入入口点的数量。例如,SaTC 在 17 个 Netgear 样本中发现了 31,000 多个后端入口点,而在 9 个 D-Link 样本中仅发现了 779 个入口点,因此 Netgear 样本的平均分析时间比 D-Link 长 14 小时样品(如表 5 所示)。相比之下,KARONTE 花费的时间取决于在边界二进制文件中找到的数据密钥的数量,这些数据用于标记 IPC(进程间通信)范例。例如,SaTC 在 7 个 Tenda 样本中发现了 10,228 个敏感入口点,但 KARONTE 发现了不到 100 个数据键。因此,KARONTE 在 Tenda 样本上比 SaTC 更快。
Case Study: Command Injection.
listing 4 显示了 SaTC 检测到的 D-Link DIR 878 中的命令注入漏洞。前端 HTML 文件 Network.html 包含输入关键字 SetNetworkSettings/IPAddress(第 4 行)。我们的输入输入模块在边界二进制文件 prog.cgi(第 10 行)中检测到关键字的引用。跨进程入口查找器根据共享字符串 SysLogRemote_IPAddress 恢复 prog.cgi 和 rc 之间的数据依赖关系,并在函数 FUN_44fa0c(第 17 行)中找到使用输入数据的代码片段的入口。输入敏感的污点分析模块在第 28 行找到对接收器函数 twsystem 的调用跟踪,并根据路径探索结果和路径约束(第 25 行)发出警报。
listing 4: Pseudocode of CVE-2019-8312 SaTC 在第 28 行检测到的命令注入漏洞。

Case Study: Incorrect Access Control. 我们根据 SaTC 识别的动作关键字发现设备的错误访问控制漏洞。首先,我们发送带有 action 关键字的请求,以触发设备后端的相应处理程序函数。然后,我们检查响应并验证设备的 API 是否正确限制访问。在我们的数据集中,我们发现了六个可能导致隐私泄露的错误访问控制漏洞。例如,在 CVE-2019-7388 中,D-Link 823G 错误地限制了未经授权的参与者对资源的访问。攻击者只需远程调用HNAP API GetClientInfo,即可获取无线局域网(WLAN)中所有客户端的信息,如IP地址、MAC地址、设备名称等。
这里主要是对比了访问控制以及命令注入的漏洞,因为这两种漏洞是karnote所不具备检测的
0x72 Accuracy of Keyword Extraction
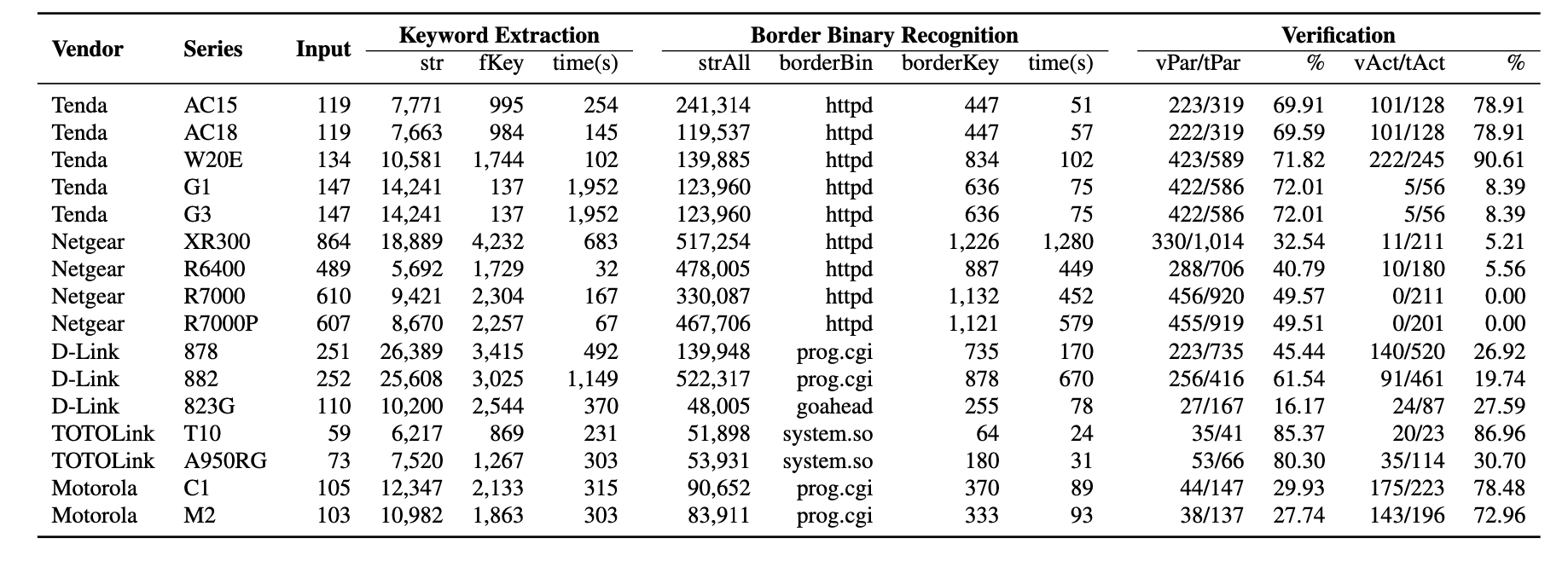
表 4 的 Ksrc 列显示了找到漏洞相关关键字的前端文件的类型。 33 个错误中有 20 个与 JavaScript 文件中的输入关键字有关;八是与 XML 文件中的关键字有关;其中四个依赖于 HTML 文件中的关键字。在 33 个 bug 中,只有两个与 HTML 文件的表单组件中的关键字有关(在表 4 中标记为 HTML+)。对于 XR300 中的错误,我们使用隐式查找器来识别更接近另一个正常定位的条目的条目。结果意味着在输入关键字提取 (§3) 中使用的所有三种类型的前端文件都是定位输入条目所必需的。表 8 显示了 SaTC 在评估过程中每一步选择的输入关键词的数量。来自前端文件的所有字符串中只有 10% 最终用作输入关键字。
表八 Input keywords collected, filtered and used during our evaluation. 对于每个设备,我们提供前端文件(输入)的数量。对于输入关键字提取,该表显示了未过滤关键字(str)、过滤关键字(fKey)和分析时间的数量。对于边界二进制识别,我们显示后端二进制文件中所有字符串的数量(strAll)、边界二进制文件名称(borderBin)以及边界二进制文件中匹配的关键字(borderKey)。在验证部分,(vPar)和(tPar)代表已验证和总参数关键字的数量,而(vAct)和(tAct)代表已验证和总动作关键字的数量; %代表比例。除了 httpd,Netgear 示例还包含其他服务的边界二进制文件,例如 upnpd。
False Positive of Parameter Keywords. 为了理解输入关键字提取(第 3 节)的误报,我们扩展第 4 节中的输入条目定位器以查找所有数据检索函数。这些函数通常用于从带有参数关键字的请求包中获取输入数据,例如函数WebsGetVar。我们将这些函数使用的参数关键字视为真阳性。对于其他参数关键字,我们采用人工分析:如果它们用于标记一些相关请求中的一些用户输入,我们将它们视为真阳性;否则,它们是误报。
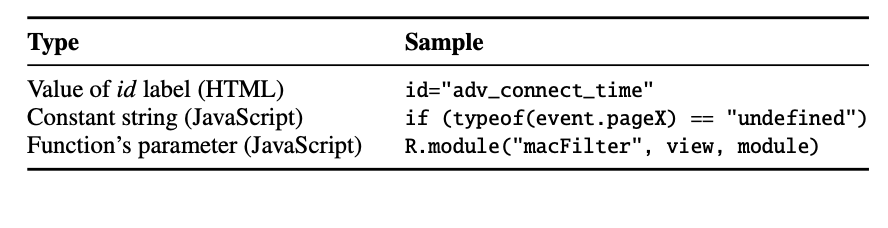
如表 8 的 vPar/tPar 列所示,SaTC 在参数关键字中收集了可持续的真阳性,特别是对于 TOTOLink(80%)、Tenda 样本(69%)和 Netgear 样本(32%)。对于 D-Link 和摩托罗拉的设备,真阳性率相对较低,这意味着 SaTC 收集的假阳性关键字较多。我们手动分析了这些误报,并在表 7 中显示了常见原因。大多数误报是常量字符串、函数的参数和 id 标签的值。我们计划调查这些误报,并将在输入关键字提取模块中添加相应的方法来过滤掉它们。
表七 Categories of the false positives of the keywords. 在这个表中,我们列出了类型(Type)和示例案例(Sample)。
False Positives of Action Keywords. 我们采用类似于上面的方法来检查动作关键字的误报。关键的区别在于我们只使用类似寄存器的函数来搜索真阳性,例如清单 1 中的 Register_Handler。表 8 的 vAct/tAct 列显示了我们的验证结果。对于腾达、TOTOLink 和摩托罗拉的大多数设备,SaTC 可以达到高于 70% 的真阳性率。对于其他设备,真阳性率较低,甚至两个 Netgear 路由器的真阳性率都为零。我们手动检查了这些结果,发现在我们的验证方法下导致 SaTC 具有显着误报率的一个常见原因是:真实动作关键字未用于注册或调用处理程序函数;例如,Netgear R7000路由器将所有处理函数的函数指针存储在一个函数调用表中,仅使用action关键字来获取表中关联函数的索引。这样,即使 SaTC 成功识别了真实动作关键字,我们依赖类寄存器功能的验证方法也无法确认其正确性。我们计划为特定设备识别此类代码模式,并定义特定规则以正确处理它们。
False Negative. 为了理解我们的错误检测结果的假阴性,我们保守地将边界二进制文件中的所有字符串视为污点源,并为每个字符串启动数据流跟踪。我们在这里的目标是检查我们是否可以从前端没有出现的后端字符串开始有效地找到漏洞。由于这个实验依赖于繁琐的人工验证每个警报(真阳性与否),我们随机选择七个设备进行假阴性验证。我们让每个设备的污点引擎一直运行,直到所有字符串都经过测试,这需要 5 到 113 个小时。对于所有 408 个报告的警报,我们手动检查它们是否为真阳性。根据我们的分析,除了腾达 AC18 中两个与字符串 cmdinput 和 data 相关的情况外,所有与前端缺少的字符串相关的警报都被确认为误报。字符串 cmdinput 不会出现在前端,数据存在于 main.js 中,但会被输入关键字提取模块过滤,因为许多前端文件都使用它(参见第 3 节)。结果表明,与以繁琐的方式测试所有后端字符串相比,SaTC 只引入了很少的假阴性(408 个中的 2 个)。
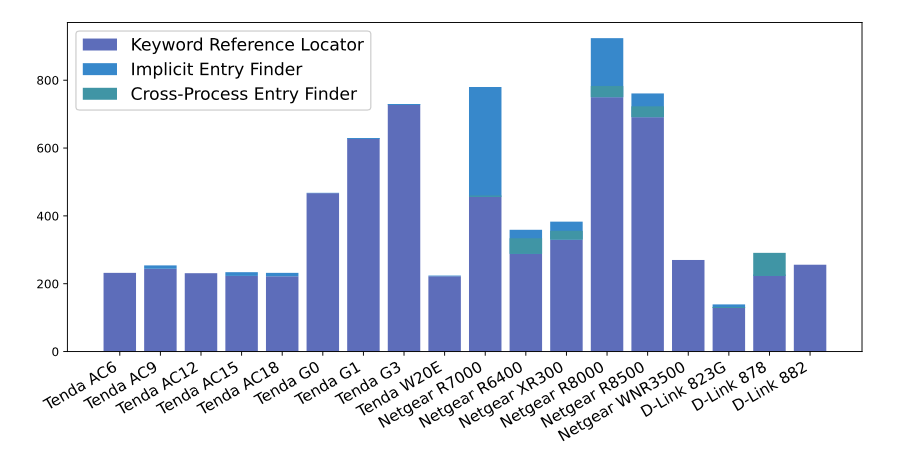
Source of True Input Keywords. 图 6 列出了关键字引用定位器、隐式条目查找器和跨进程条目查找器检测到的每个样本中的关键字数量。我们可以看到大部分输入的关键词都是由关键词引用定位器收集的,尤其是腾达设备。 Netgear 样本包含相对较多的隐式条目查找器定位的关键字,而 D-Link 样本包含更多与不同二进制文件之间共享数据相关的关键字。
图六:关键字引用定位器、隐式条目查找器和跨进程条目查找器检测到的关键字数。
0x73 Efficacy of Taint Analysis
我们进一步检查了污点分析过程,以了解我们在 5 中提出的三个优化的好处。
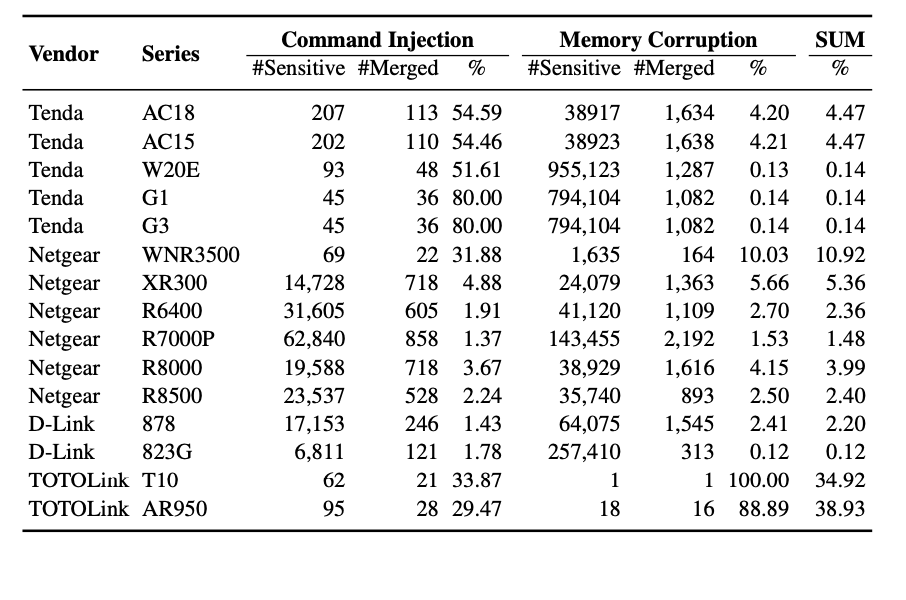
Trace Merging. SaTC 通过将调用跟踪与相同的输入条目(第 5.2 节)合并来减少要探索的路径数量。表 9 显示了跟踪合并之前和之后探索的路径数。结果证实了trace合并策略是有用的:对于有很多敏感trace到sink函数的Netgear、D-Link和Tenda设备,SaTC合并了89%以上的冗余路径;对于其他设备,此技术还合并了超过 61% 的起点。
表九 Performance of Trace Merging. 我们列出了敏感轨迹的数量(#Sensitive)、轨迹合并后的路径数(#Merging)和合并轨迹的比例(%)。
Path prioritization. SaTC 在 Netgear 样本中发现了五个解析器和清理器函数。其中三个用于对字符实体进行编码。其中两个用于解析输入字符串、转义字符并生成内部变量。
Taint Engine. 对于表 9 中的所有固件样本,SaTC 发出了 101 次警报,其中 46 次是真阳性。我们手动分析了警报中的 20 个误报。如listing 5 所示,由于缺少公共函数(例如 atoi)的抽象,会出现一些过度污染的问题。字符变量 pIndex 的污点状态被传递给一个整数变量(第 8 行),该变量用作索引以从列表中提取数据并将数据存储到字符串 sUserId 中(第 9 行)。 SaTC 发出警报是因为 v6 最终会影响 doSystemCmd 函数(第 10 行)。实际上,攻击者无法通过接口关键字 vpnUserIndex 来控制字符串。
Listing 5 : 假阳性样本的伪代码

对与存在命令注入,但命令参数不可控的地方要清除,以免影响
0x80 Discussion
在本节中,我们将讨论 SaTC 的能力和局限性,并探讨未来的改进方向。
Circle of Competence. 我们的评估表明,物联网设备不同组件之间的共享关键字可以有效地桥接复杂数据流中的点。这条短路径节省了大量分析工作,从而提高了错误查找的效率。事实上,我们可以扩展 SaTC 来检测其他系统中的错误,只要它们使用共享关键字来传递数据即可。例如,环境变量在恶意软件应用程序中被广泛用作共享信息的隐秘方式。在这种情况下,我们可以使用相同的变量名称来查找不同恶意软件进程之间的连接,并帮助检测恶意软件中的关键操作。
如扩展到网络设备中,但网络设备表单以及跳转代码在HTML中,如果需要考虑反射型XSS的话,还需进一步改进SaTC中对HTML标签的正则匹配
Implicit Data Dependency. 在我们的评估中,我们发现了几种情况,后端程序中的输入条目在前端没有对应的关键字。我们的隐式条目定位器(第 4 节)帮助 SaTC 缓解此问题以检测更多隐式输入条目。然而,在某些情况下,即使是隐式条目定位器也无法建立连接,其中 SaTC 将错过与这些条目相关的潜在错误。例如,在旧漏洞 CVE-2019-7298 中,后端程序直接从 HTTP 消息中读取数据,不使用任何关键字(更多详细信息见清单 6),因此 SaTC 会遗漏此漏洞。又如,D-Link 823G的固件使用函数apmib_set和apmib_get在不同函数之间共享数据,不使用任何关键字。 SaTC 将错过相关的漏洞 CVE-2019-7297。我们将分析更多的案例和攻击面,并尝试寻找隐藏的模式来构建前后端之间的关系,从而增强发现漏洞的能力。
直接读取body 而不传入关键字,在静态分析时将strings作为污点标记出来
Listing 6 Pseudocode of CVE-2019-7298. 设备使用家庭网络管理协议(HNAP)为用户提供配置和管理服务。但是,在处理HNAP的POST请求时,sub_42383C函数并没有对消息体进行检查和过滤,而是通过执行echo命令(第8行)直接将其写入日志文件中。恶意消息体将导致命令注入漏洞。

Efficiency v.s. Completeness. 分析效率和错误完整性是任何错误检测机制的两个关键因素。与之前的工作如 KARONTE 相比,SaTC 用错误发现的完整性来换取分析效率。一方面,该方法将帮助我们更及时地检测与前端相关的漏洞。根据我们在 §7.2 中的评估,以蛮力方式测试后端的所有潜在数据条目需要五倍的努力。另一方面,如果后端条目没有与前端关联的共享字符串,或者无法通过启发式方法检测到条目,我们的工具可能会导致漏报。幸运的是,实证评估表明,我们的方法对来自两个供应商的七种设备引入了很少的假阴性。因此,SaTC 在分析完整性和错误发现效率之间实现了经验上合理的平衡。
Encryption and Obfuscation. 由于物联网设备中的大多数安全威胁存在于应用层和网络层,部分物联网设备制造商采用代码加密或混淆来保护知识产权免受逆向工程攻击。这些混淆技术将限制 SaTC 的功能。例如,字符串加密技术可能会阻碍 SaTC 构建前端和后端之间的关系。我们将处理这些混淆技术的解决方案留给未来的工作。
为了衡量 SaTC 在加密和混淆问题上的适用性,我们进行了实证评估。具体来说,我们收集了来自 7 家领先供应商的 186 款广泛使用的家用 Wi-Fi 路由器,并检查它们以发现加密和混淆。我们发现 186 台设备中只有 4 台受到加密保护,而且都是 D-Link 路由器。在我们手动解码这四个样本后,SaTC 可以像处理其他设备一样处理它们。我们可以使用现成的解包工具(例如 binwalk)来解包所有设备,除了由于不受支持的文件系统(Tenda AC11)导致的一个故障。只有一台设备,特别是 NetGear R6400 v2,使用混淆来保护部分前端 JavaScript 代码,SaTC 未能从这些 JavaScript 文件中提取任何关键字。然而,HTML 文件并没有被混淆,SaTC 仍然可以提取出许多有用的关键字,并成功发现了两个命令注入漏洞。总体而言,加密和混淆技术尚未在现实世界的物联网设备中得到广泛应用,SaTC 仍然能够发现大量固件样本的漏洞。我们计划使用现有的反混淆方法使 SaTC 更适用。
0x90 Related Work
我们没有列出所有相关工作,而是将讨论重点放在最相关的工作上:固件漏洞发现的动态和静态方法,以及污点跟踪。
Dynamic Analysis. 许多作品使用模糊测试技术来检测物联网设备中的漏洞。 SR- Fuzzer是一种用于测试物理 SOHO(小型办公室/家庭办公室)路由器的自动化模糊测试框架,它需要首先捕获来自运行设备的大量 Web 请求,然后才能对用户输入语义进行建模以生成测试用例。 FIRMADYNE是最先进的固件仿真框架,专为大规模嵌入式固件的自动动态分析而设计。尽管 FIRMADYNE 很有前景,但其网络可达性和 Web 服务可用性的仿真率相当低。 FIRMAE 使用几种启发式方法来解决问题并提高仿真成功率。但是,它只能处理观察到的情况,可能不适用于新设备和新配置。 IoTFuzzer试图通过他们的官方应用程序找到物联网设备中的内存损坏漏洞,因此它是无固件的。然而,它被困在代码和攻击面的覆盖范围内,这是动态模糊分析的常见挑战。 FIRM-AFL是一种通过模拟目标固件用于物联网设备的灰盒模糊器。然而,研究人员很难对各种 CPU 架构进行忠实的仿真。
Static Analysis. 基于静态分析的技术在物联网漏洞检测领域非常普遍。 KARONTE 利用静态分析技术来执行多二进制污点分析。然而,研究人员只关注后端二进制文件,而忽略了存储在前端文件中的用户输入上下文,这会导致大量的漏报。 Firmalice 提供了一个框架,用于检测基于符号执行和程序切片的二进制固件中的身份验证绕过漏洞。然而,它受到约束求解器的压倒性影响。 FIE 利用符号执行来分析开源 MSP430 固件程序。然而,对于某些固件,完整的分析是难以处理的,分析中的各种不精确来源可能会导致误报或漏报。
Taint Tracking. 一些先前的工作使用污点分析来发现物联网设备中的漏洞。 DTaint专注于 recv 和其他类似函数生成的数据,但它忽略了前端文件的语义。 CryptoREX 仅识别物联网设备的密码滥用问题。一些研究人员专注于提高污点分析的可用性。 TaintInduce 试图通过从指令对中学习特定于平台的污点传播规则来提高单个传播规则的准确性。 Greyone 提出了一种模糊驱动的污点推理解决方案 FTI,用于获取更多污点属性以及输入偏移和分支之间的精确关系。 Neutaint 使用神经程序嵌入来跟踪信息流,并利用符号执行生成高质量的训练数据以提高流覆盖率。然而,累积的错误和巨大的消耗仍然是 Dynamic Taint Track 的一大挑战。
0x100 Conclusions
我们提出 SaTC,这是一种检测嵌入式系统中安全漏洞的新方法。基于变量名称在前端文件和后端函数之间共享的见解,SaTC 精确识别后端二进制文件中的输入条目。然后,它利用我们为嵌入式系统定制的污点引擎来有效检测对不可信输入的危险使用。 SaTC 已成功从 39 个固件样本中发现了 33 个0day软件漏洞,其中 30 个已获得 CVE/CNVD/PSV ID。我们的评估结果表明 SaTC 在发现固件样本中的错误方面优于最先进的工具。
Acknowledgement
我们要感谢我们的牧羊人 Kevin Butler 博士和这项工作的匿名审稿人,感谢他们提供的有益反馈。我们感谢Yue Liu、Yuwei Liu、Minghang Shen、Huikai Xu 和 Chutong Liu 对本文早期草稿的宝贵反馈。这项研究得到了国家自然科学基金项目 U1836113、61772308、61972224 和 U1736209 的部分支持,北京新星科技计划项目 Z191100001119131,BNRist 网络和软件研究计划项目的部分支持。基金BNR2019TD01004和BNR2019RC01009,国家重点研发计划项目2019QY0703,上海市科委研究计划项目20511102002。本文中表达的所有观点仅代表作者个人观点。